
Presumably, OLS is one of the ways to estimate a . How does does the OLS estimate look like?
Geometrically, the OLS estimate is the orthogonal projection of y onto to the X plane.
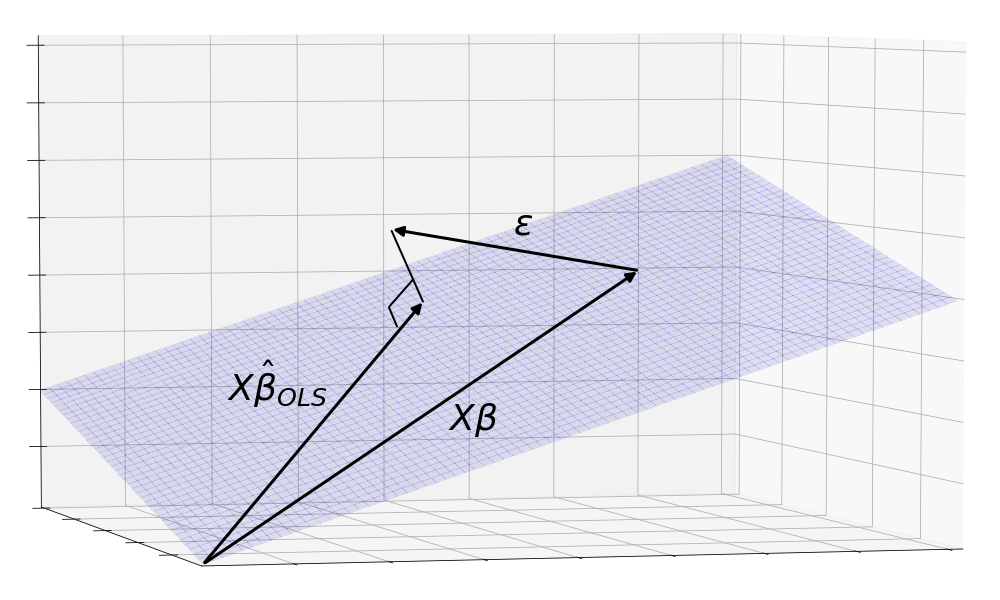
But to take into account the possible observations of , a more realistic picture is the orthogonal projection of the sphere onto the plane.
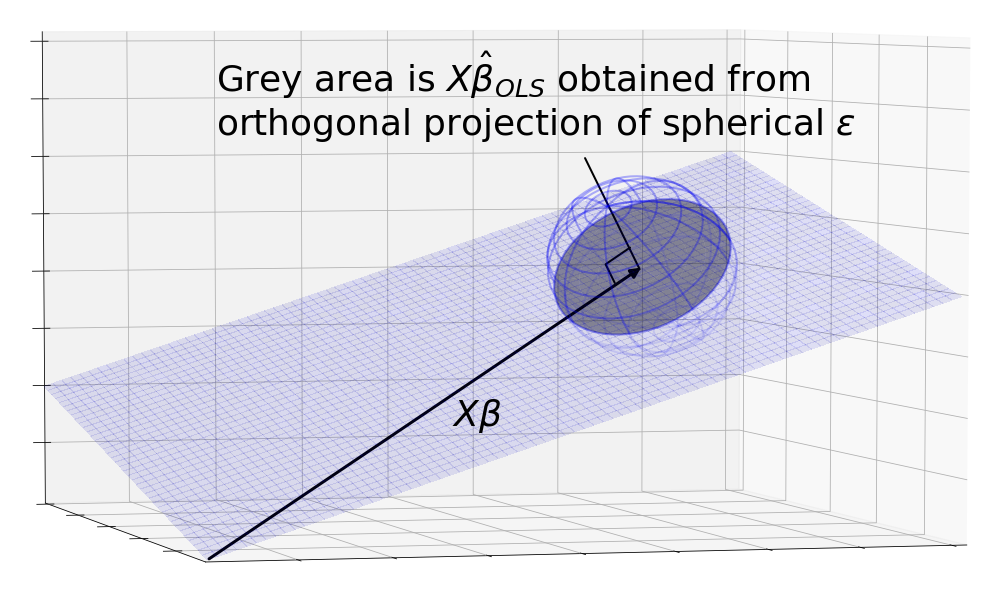
Okay, but why does OLS result in an orthogonal projection?
Recall the definition of the ordinary least squares estimator :
where is the sum of squares distance away from the observed . Formally:
We can sketch out contour lines around y that maintain the same sum of squares distances from . These points form a circle because the definition of a circle, , is exactly the points that hold sum of squares constant. The smallest circle to touch the plane touches it a tangent. At this point, both the curve and the plane have the same gradient, so the normal line to the plane must point where the normal line of the curve is pointing, which is directly at in the center of the circle.
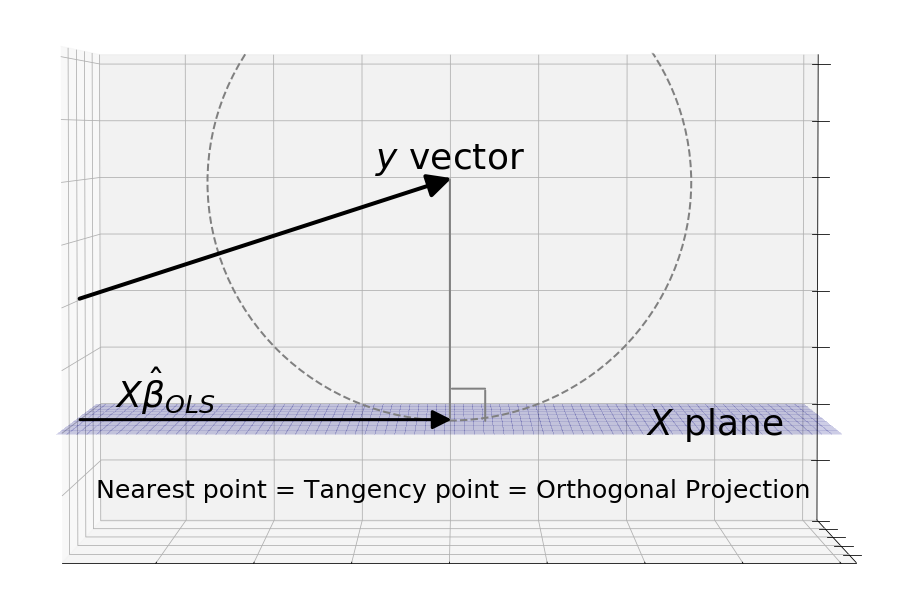
Now we know how the OLS estimator looks like geometrically. Why does Gauss-Markov say it is best?
We first need to scrutinize the meaning of the word “best”. The metric that the Gauss-Markov theorem uses to evaluate estimators is mean squared error. As with OLS, the squaring tells us we can think of it as the standard Euclidean distance we know and love. But instead of simply going through each of the possible s in the projected area and summing their distances from the One True , we have to find the mean and that requires us to weigh each distance by the probability of finding there.
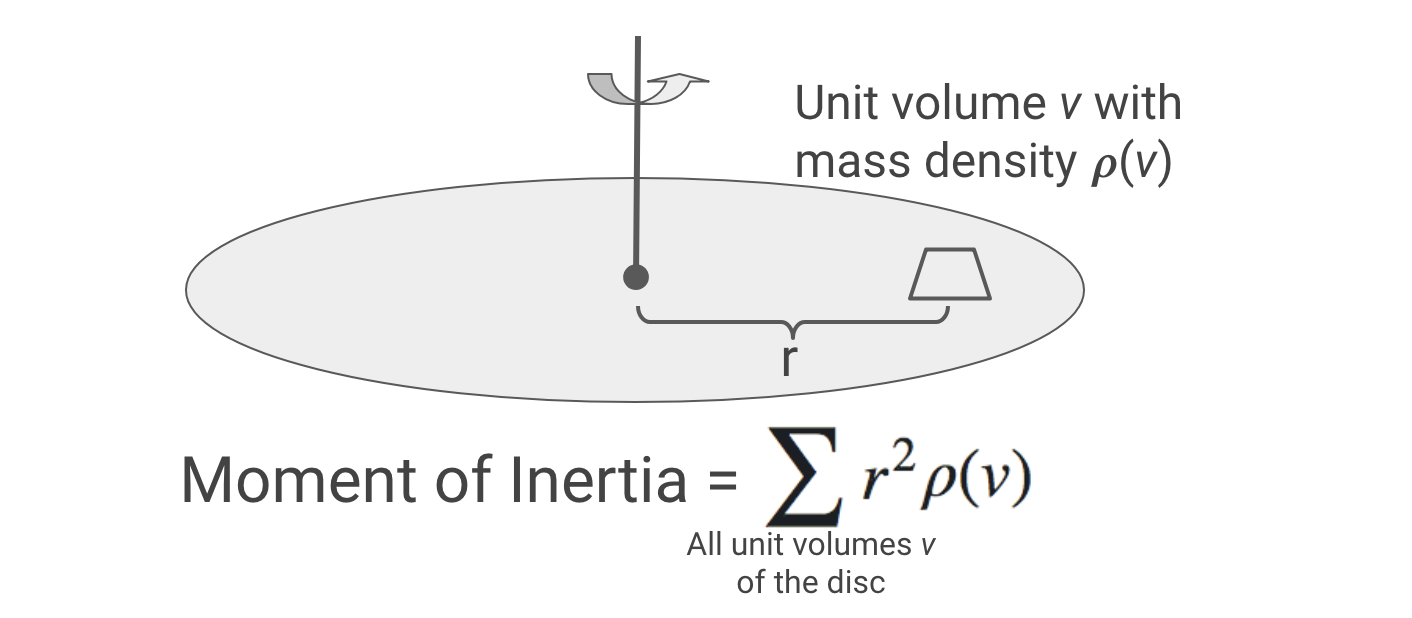
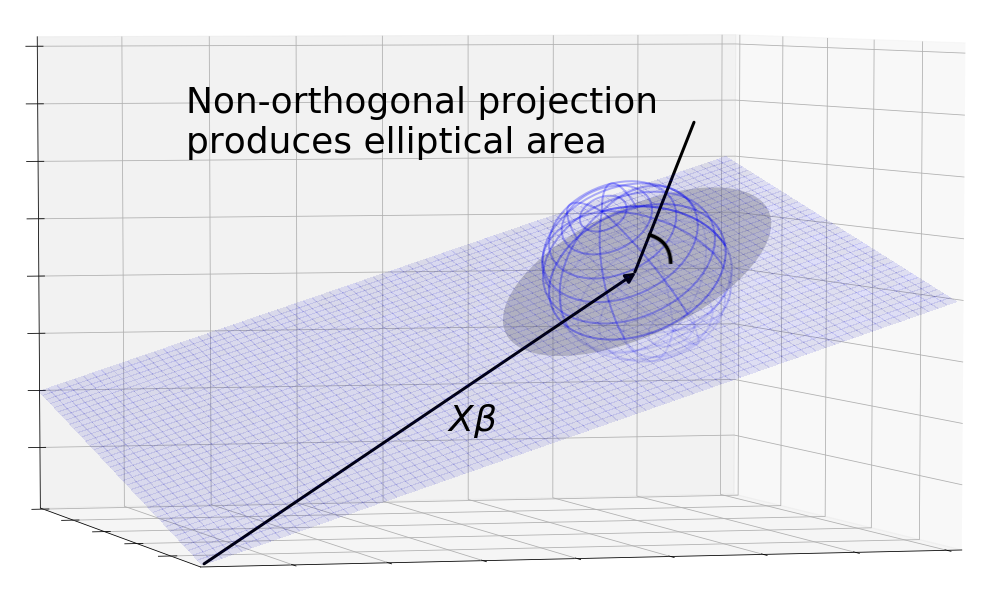
Visualizing this metric is difficult because of the probabilty weights. The most naive approach using size of the area isn’t good enough because it gives equal weight to each unit area. Instead, we can think of the metric as rotational mass, or what physicists call “moment of inertia”. Imagine the s as little unit volumes, their probabilities as their mass densities, and their distance from as their radius of rotation. A good area under the Gauss-Markov theorem, would thus have a small moment of inertia when spun about .
The Gauss-Markov theorem says that when the noise is distributed as a sphere centered around , the orthogonal projection (the OLS estimator) gives an area with the smallest moment of inertia.
We can get a sense for why this is true by looking at a non-orthogonal projection. The diagram shows that the sphere is projected onto an ellipse which has a higher moment of intertia than the circle because the mass is the same but distributed further from the center on average.
I noticed that the formal conditions of Gauss-Markov are that and . How does this translate into a sphere centered on ?
Continuing the idea of expectations as masses, tells us that the mass of the s are centered at 0. Since , it means that the cloud is a sphere centered at .
is a standard covariance matrix and it describes the shape of the cloud. The diagonal elements tell us the variance in one dimension, since all the of them are , we know that the variation of the cloud along each of the axes is the same. The off-diagonal terms tell us if there is extra stretching between axes. Here they are zero, so we know that the variation is the same in all directions which is exactly what a sphere is.
Anatomy of a covariance matrix:
Do we know why Gauss-Markov requires the centered sphere assumption? Why does the theorem break down without it?
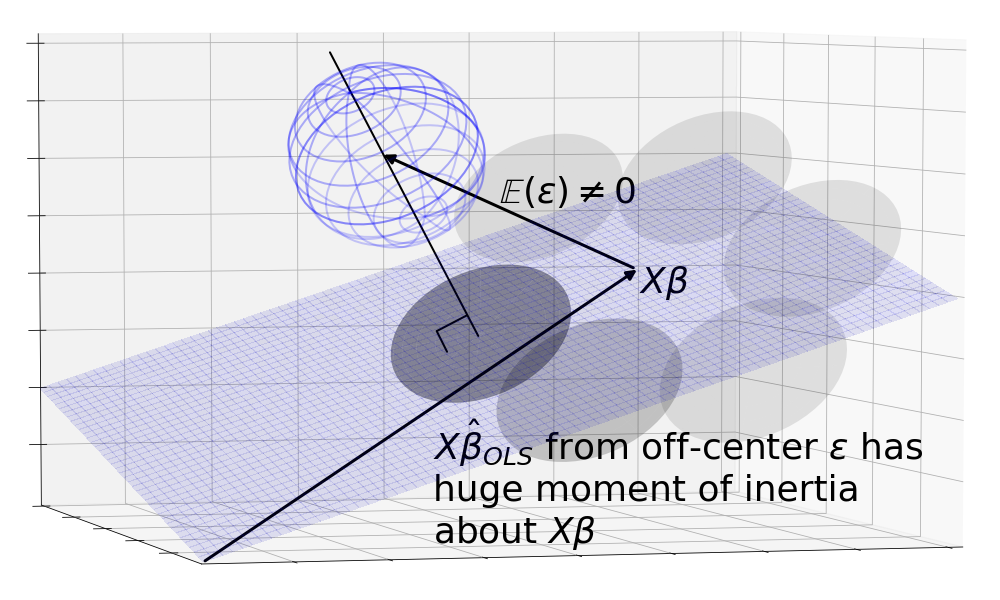
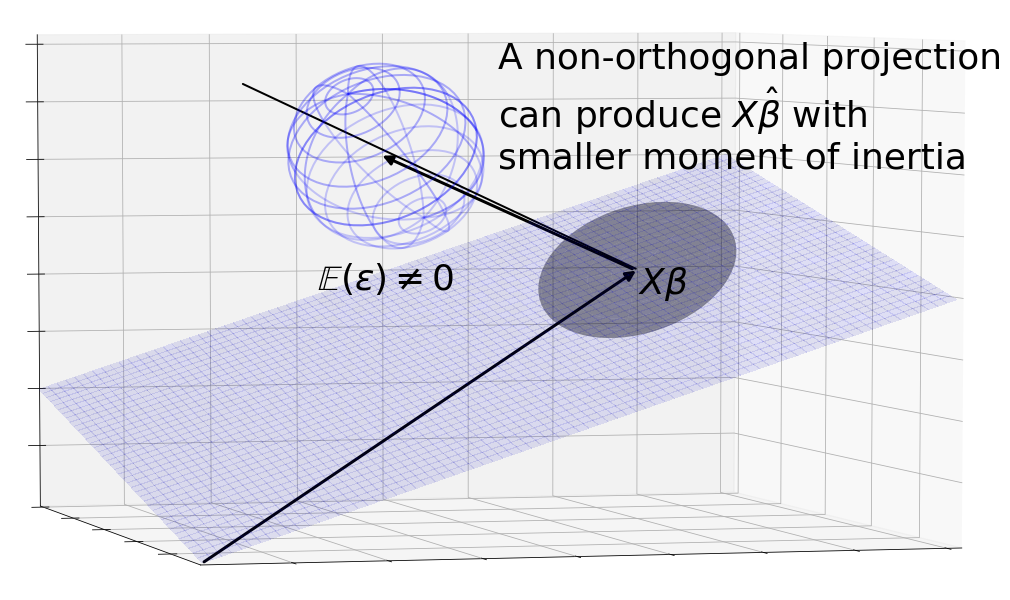
This is where we can use this geometric environment to explore the Gauss-Markov theorem. Say we were to break the centering assumption, that . The and its projection would no longer be centered around . Immediately, we run into the problem that is no longer an unbiased estimator since the center of mass of the area lies away from . Even if we were to ignore this, the OLS estimator is no longer the best: We can construct a non-orthogonal projection that projects the sphere back around resulting in a lower moment of inertia about .
We can break the spherical assumption which supposes by assuming unequal terms on the diagonals and non-zero terms on the off-diagonals. This causes to be a skewed ellipsoid. The orthogonal projection results in an ellipse. But we can imagine a non-orthogonal projection lined up with the major axis of the ellipsoid that casts a smaller area around , again resulting in lower moment of inertia.
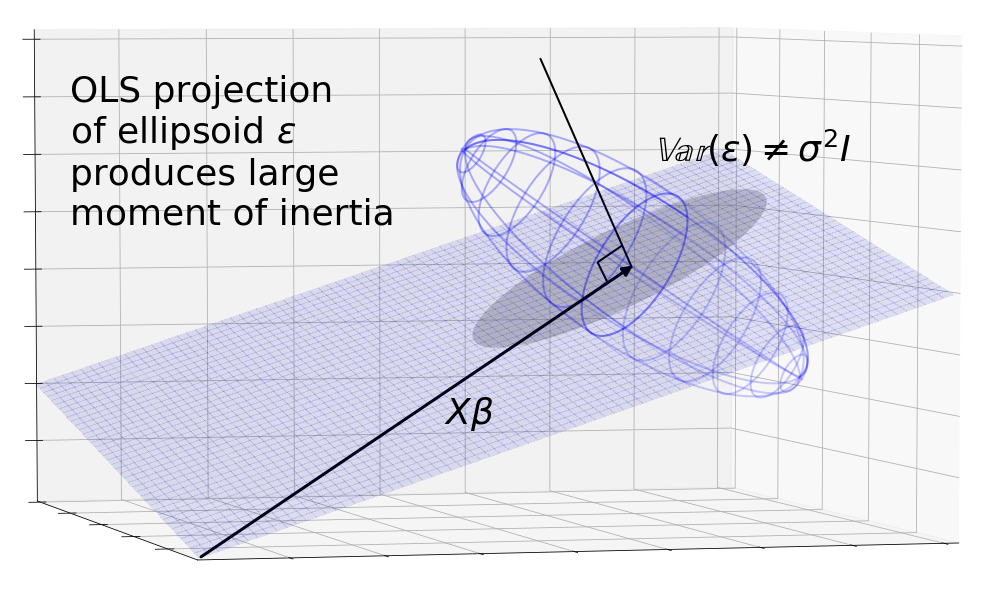
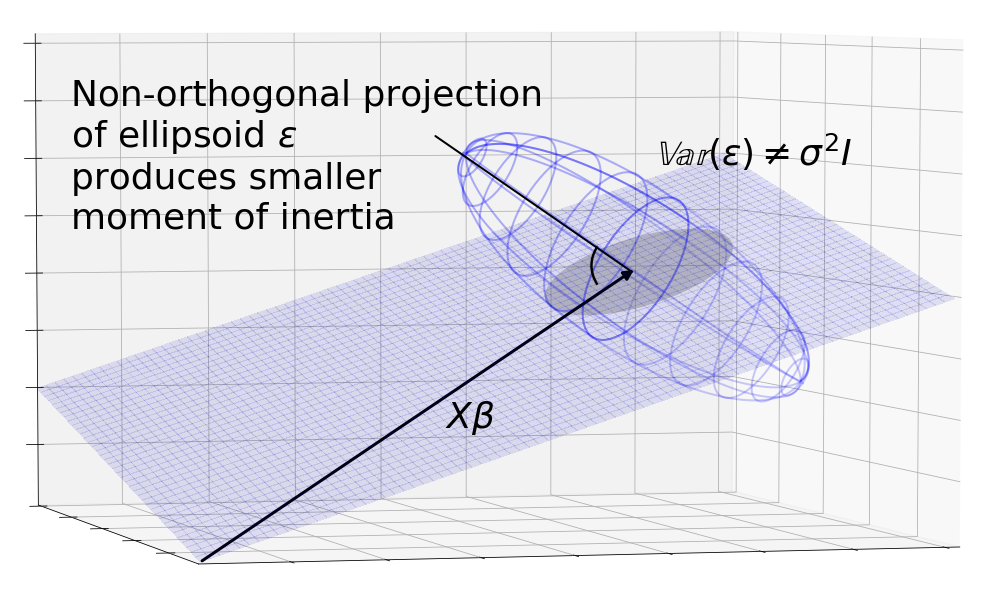
In both of these cases, we see that the OLS orthogonal projection is no longer the best.
In practice, we won’t know or the covariance matrix of . Without this information, how are we going to find the best angle to project from in order to beat the OLS estimator?
The crux of this question is the distinction between existence and derivation of an OLS-beating estimator. The Gauss-Markov theorem is making the bolder of the two statement that when the conditions are right, no better estimator, derivable or not, exists. Conversely, the theorem is also more fragile when the conditions are missing — we only need to show that an OLS-beating estimator exists.
Are you sure that’s right? If we are allowed to design better estimators using the information from the secret control room of the universe, doesn’t this estimator beat OLS? Take the OLS estimate, shrink it into a circle that has half the radius of the original.
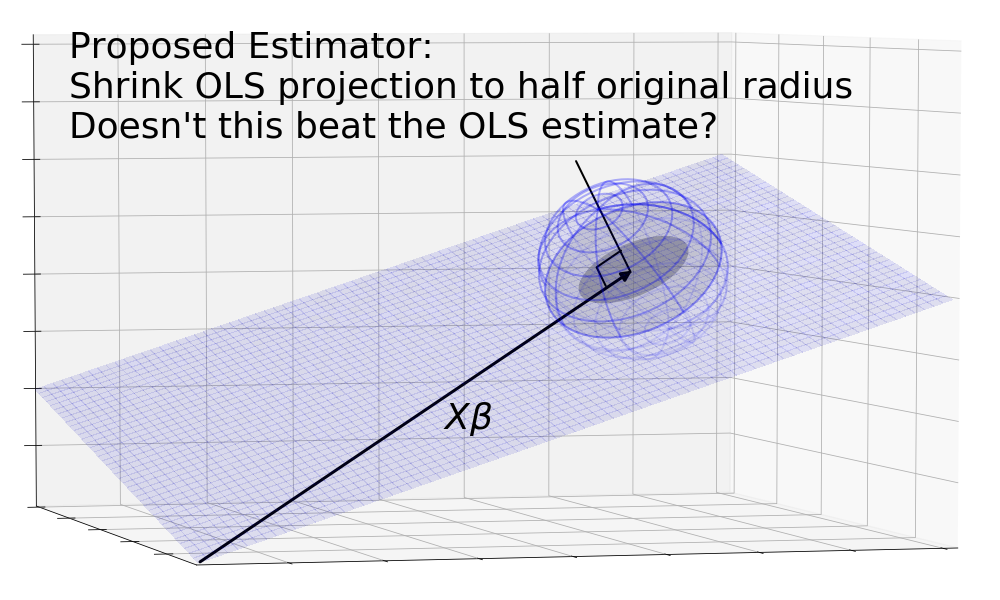
The problem with this estimator is that it is not linear and therefore not a refutation of the Gauss-Markov theorem. Remember that for an estimator to be linear, it needs to be a linear combination of its inputs. In this case, we’re estimating (and by proxy ) using , or more specifically the columns of , as the input. As such if we pass in a zero vector as , the resulting estimate must be zero since any linear combination of zeros is zero. This means linear transformations that stretch or shrink must be centered on zero instead of otherwise the zero vector would be pulled away from zero, resulting in a non-zero output vector.
On the other hand, the projections we have suggested are linear because no matter how the zero vector is projected it always remains a zero vector.